LLM Chains might be enough
A briefing on why LLM Chains might be just what you need.
Since the emergence of Transformer-based Generative models, AI has taken the world by storm. Ever since, it feels like a new term surfaces every week around AI and LLMs: vibe-coding, context engineering, agents, slop, among others.
One of the less prominent ones is "Chain," which is what we will be focusing on today.
What are Chains?
An LLM Chain is any sequenced software system that integrates an LLM in one or more parts of its execution flow.
The main purpose of this type of integration is to leverage the dynamic analysis that an LLM provides to handle different types of tasks. This can range from log analysis to content generation.
Now, you might be thinking: isn't that just an Agent?
Not exactly. Agents are built around an agentic frameworks like ReAct. We hand them tools and expect them to act autonomously. Chains, on the other hand, are conventional software systems that incorporate an LLM at some stage of their pipeline.
That does not mean chains are entirely rigid. They can incorporate conditional logic based on the LLM's output. We can use routing chains to direct execution down different branches depending on the model's response. The key distinction is that chains lack the autonomous tool-calling capability that agents have. We define every possible path ahead of time; the LLM does not get to invent new ones.
Why is everyone focused on Agents?
In my experience, every time I hear someone talk about building something with an LLM, there is a very high chance they are going to say "Let's build an Agent." Agents are undeniably appealing and remarkably useful when implemented correctly, but I believe they can be overkill in certain situations.
We essentially equip them with tools to accomplish a given task, hoping they pick the best-suited ones in the right order to get the job done. This layer of non-determinism can be avoided entirely if the task at hand is achievable with a chain. I think we should make it a point to evaluate whether a chain can accomplish our goal before even considering a fully-fledged agent.
Chains can be enough
When compared to Agents, chains are considerably more constrained in what they can accomplish. Their execution paths are defined upfront (even when branching is involved) and they follow those paths every time. But this predictability is precisely what makes them advantageous over Agents.
A Chain is a conventional software solution with predetermined steps; the LLM is merely a component of the overall system. We only rely on the LLM's output to drive decisions within boundaries we have already set, while the rest of the pipeline behaves predictably, giving us certainty about how a given task was carried out.
With Agents, we place our faith in them, hoping they will select the optimal tools in the ideal sequence to complete a task. The fact that we let agents decide which steps to take on their own means that we will inevitably encounter instances where we cannot steer the agent toward doing something in a specific way. The autonomy they possess is the very foundation on which most of their usefulness rests.
When should we choose chains over agents
Chains are better suited for situations where we need the guarantee that a task will be carried out in a specific, predetermined manner. The old, boring, predictable way.
They also shine in systems that require only minimal reliance on LLMs.
Let's take the following example: we want to leverage an LLM to perform automated code review on a Pull Request hosted on GitHub. We could build an agent, grant it access to the GitHub MCP server for repository interactions, and equip it with a suite of tools to handle, parse, and persist the results. Alternatively, we can build a program that invokes an LLM for the analysis and handles the rest programmatically. The agentic approach would work, but it is not necessary here. A chain can handle this task well enough.
If we plan to extend the functionality in the future, an agent may make more sense, yet introducing additional tools would increase the complexity of agentic interactions. We would need to instruct the agent to perform certain actions with specific tools in a specific order whenever its capabilities are expanded.
Since a chain does not carry this kind of non-determinism, we do not need to worry about how it will operate, even as its functionality grows.
Let's see how to implement this. The chain will do the following:
- Retrieve the diff from GitHub.
- Craft a prompt with instructions and the diff, then send it to the LLM.
- Parse the LLM response and publish the review results to the GitHub PR.
Let's start with the diff retrieval. To interact with the GitHub API, we can use Octokit. The source code can be found in the following repository.
We will make two calls to the API: one to retrieve the diff and another to fetch metadata about the PR itself.
import { Octokit } from '@octokit/rest';
export async function getPRDiff(options: PRDiffOptions): Promise<PRDiffResult> {
const { owner, repo, pullNumber, token } = options;
const octokit = new Octokit({ auth: token });
const sharedParams = { owner, repo, pull_number: pullNumber };
const [{ data: pr }, { data: diff }] = await Promise.all([
octokit.pulls.get(sharedParams),
octokit.pulls.get({ ...sharedParams, mediaType: { format: 'diff' } }),
]);
return {
diff: diff as unknown as string,
title: pr.title,
description: pr.body,
url: pr.html_url,
commitSha: pr.head.sha,
};
}Next, we need to craft a prompt that includes the diff and send it to the LLM for review. To interact with the model, we'll use LangChain alongside Google's Gemini 3 Flash. We begin by defining two prompt variants: a system prompt and a user prompt. The system prompt establishes the role we assign to the LLM, while the user prompt contains the actual query.
const SYSTEM_PROMPT = `You are an expert code reviewer. You will be given a GitHub Pull Request diff.
Your task is to perform a thorough code review and provide actionable feedback.
Focus on:
- Bugs and logical errors
- Security vulnerabilities
- Performance issues
- Code readability and maintainability
- Best practices and coding standards
- Style consistency
For each comment, specify the exact file and line number from the diff, a severity level, a category, and a clear explanation. If possible, provide a code suggestion to fix the issue.
Be constructive and concise. Only comment on things that genuinely matter. Avoid trivial nitpicks unless they indicate a pattern.
You MUST respond with valid JSON matching exactly this template:
{template}`;
const USER_PROMPT = `Please review the following Pull Request.
**Title:** {title}
**Description:** {description}
**Diff:**
\`\`\`diff
{diff}
\`\`\`
Respond ONLY with the JSON review. No additional text.`;We also define a JSON-based template so that every LLM response adheres to a consistent structure. The format does not have to be JSON. It can be in any format really. The goal of providing a template is to ensure we can parse the response reliably each time the chain runs.
{
"summary": "A brief overall summary of the code review",
"comments": [
{
"file": "The file path the comment refers to",
"line": "The line number in the diff where the comment applies",
"severity": "critical | warning | suggestion | nitpick",
"category": "bug | security | performance | readability | maintainability | style | best-practice | other",
"comment": "The review comment explaining the issue or suggestion",
"suggestion": "(Optional) A code suggestion to fix the issue"
}
]
}With both prompts and the template ready, we can wire everything together to query the model.
export async function reviewDiff(options: ReviewOptions): Promise < CodeReview > {
const {
diff,
title,
description,
apiKey,
outputPath
} = options;
const templatePath = join(\_\ _dirname, 'review-template.json');
const template = await readFile(templatePath, 'utf-8');
const model = new ChatGoogleGenerativeAI({
model: 'gemini-3-flash-preview',
apiKey,
temperature: 0.2,
});
const prompt = ChatPromptTemplate.fromMessages([
['system', SYSTEM_PROMPT],
['human', USER_PROMPT],
]);
const chain = prompt.pipe(model);
const response = await chain.invoke({
template,
title,
description: description ?? 'No description provided',
diff,
});
const content =
typeof response.content === 'string' ? response.content : JSON.stringify(response.content);
const jsonMatch = content.match(/`json\s*([\s\S]*?)`/) ?? content.match(/(\{[\s\S]\*\})/);
if (!jsonMatch) {
throw new Error('Failed to extract JSON from LLM response');
}
const review: CodeReview = JSON.parse(jsonMatch[1] !.trim());
const output = outputPath ?? join(process.cwd(), `review-${crypto.randomUUID()}.json`);
await writeFile(output, JSON.stringify(review, null, 2), 'utf-8');
console.log(`Review saved to ${output}`);
return review;
}Worth noting: when instructed to return JSON, LLMs tend to wrap the payload in Markdown code fences (prefixed with "```json" and closed with "```"). That is why we use a regex to strip those delimiters from the response.
Now we can take the parsed review and publish its comments directly to the GitHub Pull Request.
export async function publishReview(options: PublishReviewOptions): Promise<void> {
const { owner, repo, pullNumber, token, review, commitId, diff } = options;
const octokit = new Octokit({ auth: token });
const sharedParams = { owner, repo, pull_number: pullNumber, commit_id: commitId };
const { inline, fileLvel } = classifyComments(review.comments, parseDiffLines(diff));
await octokit.pulls.createReview({
...sharedParams,
body: buildReviewBody(review),
event: 'COMMENT',
...(inline.length > 0 ? { comments: inline } : {}),
});
await Promise.all(
fileLvel.map((fc) =>
octokit.pulls.createReviewComment({
...sharedParams,
path: fc.path,
body: fc.body,
subject_type: 'file',
})
)
);
console.log(
`Published review to PR #${pullNumber} (${inline.length} inline, ${fileLvel.length} file-level)`
);
}All that remains is to wire the three functions together and the pipeline is complete:
const result = await getPRDiff({ owner, repo, pullNumber, token });
const review = await reviewDiff({
diff: result.diff,
title: result.title,
description: result.description,
apiKey: geminiApiKey,
});
await publishReview({
owner,
repo,
pullNumber,
token,
review,
commitId: result.commitSha,
diff: result.diff,
});We can then inspect the PR to see every comment and suggestion the chain produced:
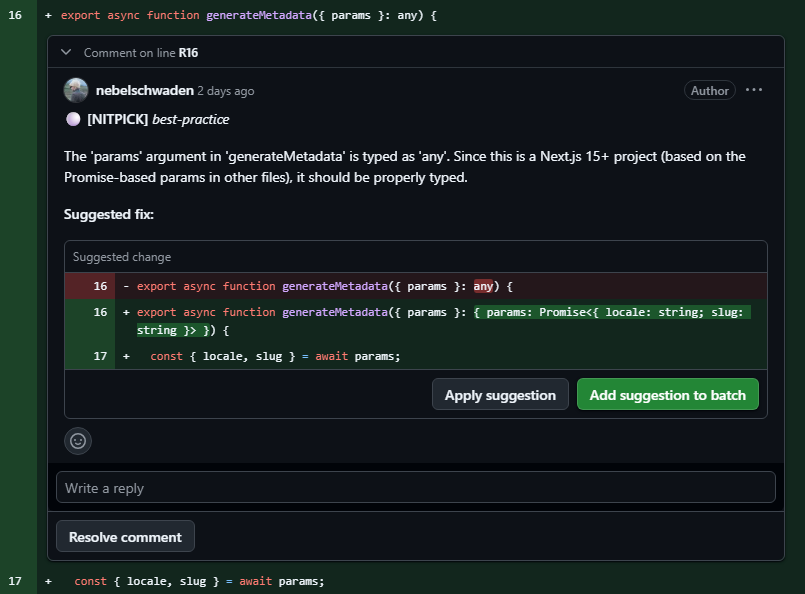
And that's it. We can expand this tool's capabilities as needed, with the guarantee that the system will maintain a deterministic execution flow.
Chaining can go well beyond what I have covered in this example, but the takeaway is clear: while agents may seem more attractive, they are certainly not the only way to leverage LLMs programmatically.